Tutorial Programme
| Day | Topic | Presenter |
| 1
(Starts at |
Open-Source EDA and Machine Learning for IC Design – A Live Update (Room – Jamavar) |
Abdelrahman Hosny, Brown University Andrew B. Kahng, UC, San Diego |
| Hardware Platforms for Artificial Intelligence (Room – Royal Ball Room) |
Manish Pandey, Synopsys Swagath Venkataramani, IBM Yu Wang, Tsinghua University |
|
| Advances in Power Management for Secure IoT and Efficient Mobile Applications (Room – Diya) |
Qadeer Khan, IIT Madras Shreyas Sen, Purdue University |
|
| 2
(Starts at |
Embedded Systems: Invisible Computing (Room – Royal Ball Room) |
Luca Carloni, Columbia University Andreas Gerstlauer, UT, Austin Tulika Mitra, NUS Sri Parameswaran, University of New South Wales |
| Secure Circuits and Systems (Room – Jamavar) |
Shivam Bhasin, Nanyang Technical University Makoto Ikeda, University of Tokyo Makoto Nagata, Kobe University Simha Sethumadhavan, Columbia University |
|
| Resiliency and Testability: Key Drivers for Self-Driving Vehicles (Room – Diya) |
J. A. Abraham, University of Texas, Austin, USA Shawn Blanton, Carnegie Mellon University, USA Abhijit Chatterjee, Georgia Tech University, USA Nirmal Saxena, NVidia, USA |
Day 1
Tutorial 1 : Open-Source EDA and Machine Learning for IC Design – A Live Update (Starts at 9:30 AM)
Speakers:
Andrew B. Kahng, University of California, San Diego
Abdelrahman Hosny, Brown University
Abstract:
Open-source EDA is rapidly enabling new waves of innovation on many fronts. For academic researchers, it speeds up the lifecycle of scientific progress and makes research results relevant to modern industry practice. For EDA professionals and the industry ecosystem, open-source EDA is a complement and booster to commercial EDA. For the IC design community, recent releases under permissive licenses make it possible for design engineers as well as hobbyists to take ideas to manufacturing-ready layout at essentially zero cost.
This full-day tutorial will review the very latest progress in open-source EDA, focusing on the digital RTL-to-GDS flow. In particular, the tutorial will make a deep dive into The OpenROAD Project https://theopenroadproject.org/ , which brings new open-source tools and machine learning into a “no human in the loop” RTL-to-GDS flow. OpenROAD’s key components will be reviewed, along with how the overall system is architected. Here, we will provide live / hands-on demos on using the OpenROAD flow and integrating it into existing design flows. We will then turn to industry-compatible open-source infrastructure, and then demonstrate how OpenROAD’s continuous integration (CI) system works in order to welcome new contributions and give a low-overhead start for design tool and methodology innovation. Importantly, open-source EDA and the goal of “self-driving”, no-humans IC design puts a spotlight on machine learning that reduces design effort and schedule. We will show examples of important machine learning use cases and proof points in the RTL-to-GDS flow, along with demos of an open-source, freely portable integrated metrics collection system.
The target audience of this tutorial includes EDA researchers and developers, graduate students and professors, and IC design methodologists, physical design engineers, and managers. Whether you are a veteran in EDA / IC design or just starting a career, the tutorial will give a new perspective and a roadmap to use and contribute to open-source EDA.
Speaker Bios:
Andrew B. Kahng is Professor of CSE and ECE and holder of the endowed chair in high-performance computing at UC San Diego. He was visiting scientist at Cadence (1995-97) and founder/CTO at Blaze DFM (2004-06). He is coauthor of 3 books and over 500 journal and conference papers, holds 34 issued U.S. patents, and is a fellow of ACM and IEEE. He has served as general chair of DAC, ISPD and other conferences, and from 2000-2016 as international chair/co-chair of the ITRS Design and System Drivers working groups. He is currently PI of “OpenROAD” https://theopenroadproject.org/, a $12.4M U.S. DARPA project targeting open-source, autonomous (“no human in the loop”) tools for IC implementation.
Abdelrahman Hosny is a second-year Ph.D. student in the Computer Science department at Brown University. He mixes software industry experience with his research to reimagine the Electronic Design Automation (EDA) landscape. His Ph.D. research tries to make silicon compilation catch up with advance in software compilation: free, open source and easy to use. Towards that goal, he investigates machine learning techniques (specifically, reinforcement learning) for optimizing EDA flows with no human in the loop. Abdelrahman received a Master’s degree in Computer Science and Engineering from the University of Connecticut, and a Bachelor’s degree in Computer Science from Assiut University.
Participant Info:
- Attendees from a wide range of backgrounds will be able to follow the material and demos presented.
- Active participation is encouraged if feasible for the individual attendee. For this, the attendee should bring a laptop, and we will show step-by-step instructions to download and use the necessary tools.
- For this, it is preferable that the attendee’s machine comes with:
-
- 4+ GB of memory.
- CentOS 7 installed. Or a VM (using VirtualBox) that runs CentOS.
- Internet access in the venue will enable tutorial attendees to browse repositories, download and run the tools, etc.
- A background on Tcl scripting is not required but will be a plus. A good tutorial on Tcl scripting can be found here.
A background on using git and GitHub is not required but will be a plus. For the interested attendee, we’ll post a couple of fun and informative exercises here in the weeks leading up to the tutorial and conference.
Day Agenda:
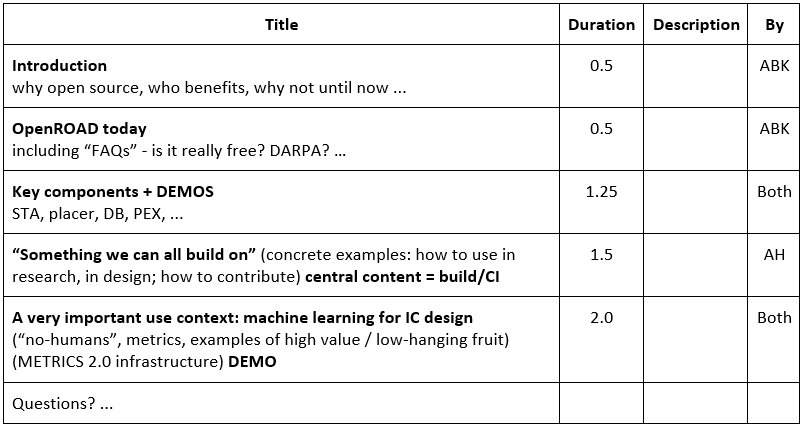
Day 1
Tutorial 2 : Hardware Platforms for Artificial Intelligence (Starts at 9:30 AM)
Organizers:
Yu Wang, Tsinghua University
Anand Raghunathan, Purdue University
Abstract:
In this tutorial, we will start with introduction to the overall trend in the hardware platform development for deep neural network applications. And then Manish Pandey from Synopsys and Swagath Venkataramani from IBM will share their insights and practices from Industry.
Speakers:
Yu Wang, Tsinghua University
Manish Pandey, Synopsys
Swagath Venkataramani, IBM
Neural Networks on Chip Design from the User Perspective
Abstract:
To apply neural networks to different applications, various customized hardware architectures are proposed in the past a few years to boost the energy efficiency of deep learning inference processing. Meanwhile, the possibilities of adopting emerging NVM (Non-Volatile Memory) technology for efficient learning systems, i.e., in-memory-computing, are also attractive for both academia and industry. We will briefly review our past effort on Deep learning Processing Unit (DPU) design on FPGA in Tsinghua and Deephi, and then talk about hardware platform trends. Furthermore, we will also talk about the challenges for flexibility, reliability, and security issues in NN accelerators other than energy efficiency from the users’ perspective, and some preliminary solutions for now.
Speaker Bio:
Yu Wang received his B.S. degree in 2002 and Ph.D. degree (with honor) in 2007 from Tsinghua University, Beijing, China. He is currently a Tenured Professor with the Department of Electronic Engineering, Tsinghua University. His research interests include application specific hardware computing, parallel circuit analysis, and power/reliability aware system design methodology. Wang has authored and coauthored over 200 papers in refereed journals and conferences. He has received Best Paper Award in ASPDAC 2019, FPGA 2017, NVMSA17, ISVLSI 2012, and Best Poster Award in HEART 2012 with 10 Best Paper Nominations. He is a recipient of DAC Under-40 Innovator Award in 2018 and IBM X10 Faculty Award in 2010. He is the co-founder of Deephi Tech (acquired by Xilinx), which is a leading deep learning computing platform provider.
Designing Hardware Accelerators for Deep Neural Networks
Abstract:
As machine learning is used in increasingly diverse applications, ranging from IoT edge devices to self-driving vehicles, specialized computing architectures and platforms have emerged as alternatives to CPUs and GPUs, to meet energy, cost and performance requirements imposed by these applications.
We start with an overview of the compute and data complexity for various neural network topologies, their underlying operations and how these can be realized as Application Specific Integrated Circuits (ASICs) or Field Programmable Gate Arrays (FPGAs). The inherent parallelism in the underlying computation allows massive parallelization. However, exploiting this parallelism requires large parallel computational arrays, as well as high-bandwidth memory accesses for weights, feature maps and inter-layer communication. These arrays, consisting of adders, multipliers, square root and division circuits consume expensive chip real estate/logic gate count. Memory accesses, necessary to store network parameters and processed data, impose high bandwidth requirements, necessitating both on-chip memory as well as high-bandwidth off-chip memory interconnects. We quantify these performance and memory bandwidth constraints for ASICs and FPGAs and discuss microarchitectural techniques to address them. We discuss how pruning, compression, and reduced precision arithmetic and quantization approaches help address these concerns.
The power and latency cost of memory accesses have prompted new near-memory and in-memory computing architectures which reduce energy cost by embedding computations at the periphery of memory structures. These architectures often employ mixed analog-digital computing and analog storage for further energy reduction.
Speaker Bio:
Manish Pandey is a Fellow and Vice President of R&D at Synopsys, and an Adjunct Professor in the ECE department at Carnegie Mellon University, where his where his research interests range broadly across intelligent edge computing, machine learning architectures, and natural language processing teaching. He leads the machine learning, formal verification and power analysis engineering teams at Synopsys. Manish Pandey has extensive experience in machine learning, distributed systems and infrastructure, and he previously led storage analytics systems at Nutanix, and the display ad targeting and security groups at Yahoo!. He earlier developed several formal verification technologies at Verplex and Cadence which are in widespread use in the industry. Manish Pandey has been the recipient of the IEEE Transaction in CAD Outstanding author award and holds over two dozen patents and refereed publications. He completed his Ph.D. in Computer Science from Carnegie Mellon University and a B.S. in Computer Science from the Indian Institute of Technology Kharagpur.
Boosting AI Efficiency Through Accelerators, Custom Compliers and Approximate Computing
Abstract:
Deep Neural Networks (DNNs) have achieved super-human levels of algorithmic performance on many Artificial Intelligence (AI) tasks involving images, videos, text and natural language. However, their superior accuracy comes at an unprecedented computational cost, outstripping the capabilities of modern CPU and GPGPU platforms. This has resulted in an AI efficiency gap, bridging which is pivotal to the ubiquitous adoption of DNNs. To this end, this tutorial summarizes three key approaches adopted by IBM Research (and broadly by others in the research community) to improve the computational efficiency of DNNs.
The first approach is the use of hardware accelerators tailored to leverage the computational characteristics of DNNs. Specifically, we will describe the RaPiD AI core, which embodies a dataflow architecture and fabricated at 14nm technology. RaPiD is designed with a 2D systolic array of processing elements to efficiently execute convolutions and matrix multiplications. It also possesses a 1D array of special function units tailored to realize low Bytes/FLOP operations such activation, normalization and pooling functions. The RaPiD core can be programmed to orchestrate various dataflows between the processing elements and memory hierarchy, balancing the trade-off between flexibility and efficiency.
The second approach involves building custom compilers to map DNN workloads onto accelerators. DNNs are static dataflow graphs and their computations can be encapsulated using using few (tens of) primitives. While this lends well to hardware acceleration, DNNs also exhibit abundant heterogeneity across layers making each layer computationally unique and to be programmed differently. To this end, we present DeepTools, a suite of software extensions that leverage and work within popular deep learning frameworks (e.g., TensorFlow). Given a DNN workload description and the target system specification, DeepTools carry out aggressive performance optimizations such as graph modifications (e.g. node ordering/fusion), optimized data-structure placement, tiling and loop orders and program generation.
The third approach, approximate computing, leverages the error resilient nature of DNNs and executes a chosen subset of computations in an approximate manner. Based on comprehensive algorithmic studies, we will describe systematic methodologies to quantize various DNN data-structures viz. activations, deactivations, weights and weight gradients with little to no loss in accuracy. We also investigate custom number representations for DNNs which further reduce compute and memory requirements.
Through an end-to-end AI system evaluation (including silicon measurements) on multiple state-of-the-art workloads, we demonstrate over an order of magnitude improvement in compute efficiency by leveraging the above approaches. We believe the tenets described in this tutorial are critical in enabling next generation AI compute platforms.
Speaker Bio:
Swagath Venkataramani is a Research Staff Member at the IBM T.J. Watson Research Center in Yorktown Heights, NY. Previously, he received his Ph.D. in Electrical and Computer Engineering from Purdue University in 2016. His research interests include hardware and software optimizations for machine/deep learning and approximate computing. His research has received multiple best paper awards and nominations and has been supported through prestigious fellowships. He is a member of the ACM.
Day 1
Tutorial 3 : Advances in Power Management for Secure IoT and Efficient Mobile Applications (Starts at 9:30 AM)
Speakers:
Shreyas Sen, Purdue University
Qadeer Khan, IIT Madras
Abstract:
With the advancement of technology in the last few decades, leading to the widespread availability of miniaturized sensors and internet-connected things (IoT), security of electronic devices has become a top priority. Side-channel attack (SCA) is one of the prominent methods to break the security of an encryption system by exploiting the information leaked from the physical devices. Correlational power attack (CPA) is an efficient power side-channel attack technique, which analyses the correlation between the estimated and measured supply current traces to extract the secret key. The existing countermeasures to the power attacks are mainly based on reducing the SNR of the leaked data, or introducing large overhead using techniques like power balancing. This talk will discuss circuits/systems that interfaces between the physical world and digital information. More specifically we will focus on fundamental improvements in sensing and communication circuits/systems. This research has applications in the areas of Internet of Things (IoT), Biomedical and Security, among others.
User interface modules such as display, touch screen, camera and haptic are an essential part of a smartphone. Since display along with touch screen is one of the most frequently accessed modules, the battery life of a smartphone is highly dependent on the power consumption of display. With the demand of high definition haptic to provide enhanced computing, visual and gaming experience on a touch screen, there is a need for highly efficient power management system which can deliver the required power without compromising with the quality of image and user experience. In this tutorial, we discuss various circuit and system level power management and control techniques to achieve high performance power efficient display and haptic interface.
Speaker Bio:
Shreyas Sen received his Ph.D. degree in Electrical and Computer Engineering from Georgia Tech, Atlanta, USA, in 2011. He is currently an Assistant Professor in School of Electrical and Computer Engineering, Purdue University. He has over 5 years of industry research experience at Intel Labs, Qualcomm and Rambus. His research interests include mixed-signal circuits/systems for Internet of Things (IoT), Biomedical and Security. He has authored/co-authored 2 book chapters, over 100 conference and journal papers and has 13 patents granted/pending.
In 2018, Shreyas Sen was chosen by MIT Technology Review as one of the top 10 Indian Inventors Worldwide under 35 (MIT TR35 India Award), for the invention of using the Human Body as a Wire, which has the potential to transform healthcare, neuroscience and human-computer interaction. Shreyas Sen is a recipient of the AFOSR Young Investigator Award 2017, NSF CISE CRII Award 2017, Google Faculty Research Award 2017, Intel Labs Divisional Recognition Award 2014 for industry-wide impact on USB-C type, Intel PhD Fellowship 2010, IEEE Microwave Fellowship 2008, GSRC Margarida Jacome Best Research Award 2007, Best Paper Awards at HOST 2017 and 2018, ICCAD Best-in-Track Award 2014, VTS Honorable Mention Award 2014, RWS Best Paper Award 2008, Intel Labs Quality Award 2012, SRC Inventor Recognition Award 2008 and Young Engineering Fellowship 2005. He serves/has served as an Associate Editor for IEEE Design & Test, Executive Committee member of IEEE Central Indiana Section, ETS and Technical Program Committee member of DAC, CICC, DATE, ISLPED, ICCAD, ITC, VLSI Design, IMSTW and VDAT. Shreyas Sen is a Senior Member of IEEE.
Qadeer Khan is an assistant professor in the Integrated Circuits and System group of the department of Electrical Engineering, Indian Institute of Technology Madras. He received the Bachelor’s degree in electronics and communication engineering from Jamia Millia Islamia University, New Delhi, India, in 1999 and the Ph.D. degree in electrical and computer engineering from Oregon State University, USA in 2012. His Ph.D. work was focused on developing novel control techniques for high performance switching dc-dc converters.
From 2012 to 2015, he worked as a staff engineer, power management systems with Qualcomm, San Diego and from 2015 to 2016 with Qualcomm, Bangalore where he was involved in defining system and architecture of various power management modules for snapdragon chipsets catering to different smartphone markets. From 1999 to 2005, he worked with Motorola and Freescale Semiconductor, India, where his main responsibilities were designing mixed-signal circuits for baseband and network processors and full-chip integrated solutions for high-voltage motor drivers.
Qadeer Khan holds 18 U.S. patents and authored/co-authored over 20 IEEE publications in the area of analog, mixed-signal and power management ICs. He serves as reviewer of the IEEE Journal of Solid-State Circuits, IEEE Transactions on Very Large Scale Integration Systems, IEEE Transaction on Power Electronics and IEEE Power Electronics Letters.
His research interests involve high-performance linear regulators, LDOs, switching dc-dc converters and power management ICs for portable electronics and energy harvesting.
Day 2
Tutorial 4 : Invisible Computing: Embedded Systems (Starts at 9:30 AM)
Speakers:
Luca Carloni, Columbia University
Andreas Gerstlauer, University of Texas at Austin
Tulika Mitra, National University of Singapore
Sri Parameswaran, University of New South Wales
Abstract:
Embedded systems are networked, low-power, high-performance, safety-critical, secure, real-time computing systems that remain invisible but provide the foundation of almost all modern electronics systems today from automotive, avionics, smart grids to medical devices, wearables and myriad consumer electronic devices. Embedded systems research is firmly driving the fourth industrial revolution that blurs the line between physical, biological, and cyber entities in the form of Cyber Physical Systems (CPS) and Internet of Things (IoT). This tutorial will cover the essential aspects of embedded systems and software design starting with the design automation of embedded architecture and security to low-power and network-level design.
Prof. Carloni will present ESP, the open-source research platform for heterogeneous system-on-chip design. ESP combines an architecture and a methodology. The flexible tile-based architecture simplifies the integration of heterogeneous components by balancing regularity and specialization. The companion methodology raises the level of abstraction to system-level design, thus promoting closer collaboration among software programmers and hardware engineers.
Prof. Mitra will present the challenges and opportunities in designing low power embedded systems. This part of the tutorial will put the spotlight on the software perspective of heterogeneous system-on-chip, especially in the context of popular emerging applications, such as machine learning and 3D gaming. We will introduce the technology trends driving heterogeneity, provide an overview of computationally divergent and performance heterogeneous multi-cores, and present compiler, runtime support to fully realize the potential of heterogeneity towards high-performance, low-power computing.
Prof. Parameswaran will present the types of attacks to which embedded systems are vulnerable and then proceed to expand on a few of the side channel attacks. Step-by-step methods will be shown which enable the attacking of embedded cicuits and systems. Some of the useful countermeasures will be described and an intuitive understanding of why these attacks are possible and the efficacy of the countermeasures will be given.
Prof. Gerstlauer will introduce edge computing that has emerged as a way to improve scalability, overhead, latency and privacy by processing large-scale data locally at the source. Such networks-of-systems (NoS) at the edge are characterized by tight real-time and resource constraints, where computations are distributed over clusters of resource-constrained edge devices communicating over often open, public networks creating new challenges. This part of the tutorial will cover methods for network-level specification, modeling, simulation, optimization, synthesis and design space exploration of such NoS at the edge.
Speaker Bio:
Luca Carloni is Professor of Computer Science at Columbia University in the City of New York. He holds a Laurea Degree Summa cum Laude in Electronics Engineering from the University of Bologna, Italy, and the MS and PhD degrees in Electrical Engineering and Computer Sciences from the University of California, Berkeley. His research interests include methodologies and tools for multi-core system-on-chip platforms with emphasis on system-level design and intellectual property reuse, design and optimization of networks-on-chip, and distributed embedded systems. He coauthored over one hundred and forty refereed papers and is the holder of two patents. Luca received the Faculty Early Career Development (CAREER) Award from the National Science Foundation in 2006, was selected as an Alfred P. Sloan Research Fellow in 2008, and received the ONR Young Investigator Award and the IEEE CEDA Early Career Award in 2010 and 2012, respectively. In 2013 Luca served as general chair of Embedded Systems Week (ESWeek), the premier event covering all aspects of embedded systems and software. Luca is an IEEE Fellow.
Andreas Gerstlauer is an Associate Professor in the Electrical and Computer Engineering Department at The University of Texas at Austin, TX, USA. He received the Ph.D. degree in Information and Computer Science from the University of California, Irvine (UCI), CA, USA, in 2004, and he was an Assistant Researcher with the Center for Embedded Computer Systems at UCI between 2004 and 2008. He has co-authored 3 books and over 100 refereed conference and journal publications. He is the recipient of a 2016-2017 Humboldt Research Fellowship, two best paper awards at DAC’16 and SAMOS’15 and several best paper nominations from, among others, DAC, DATE and HOST. He has been General and Program Chair for conferences such as MEMOCODE and CODES+ISSS, and he currently serves as Associate Editor for ACM TODAES and ACM TECS journals. His research interests include system-level design automation, system modeling, design languages and methodologies, and embedded hardware and software synthesis.
Tulika Mitra is a Professor of Computer Science at National University of Singapore (NUS). Her research interests span various aspects of the design automation of embedded real-time systems. She has authored over hundred and fifty scientific publications and holds multiple US patents. Her research has been recognized by best paper award and nominations in leading conferences. She is the recipient of the Indian Institute of Science Outstanding Woman Researcher Award 2017. Tulika is on the ACM Publications Board, Senior Associate Editor of ACM TECS, Deputy Editor-in-Chief of IEEE ESL, Associate Editor of IEEE Design & Test, IEEE Micro. She has served as program chair of EMOSFT and CASES and is the General Chair of Embedded Systems Week 2020.
Sri Parameswaran is a Professor in the School of Computer Science and Engineering at the University of New South Wales. He also serves as the Acting Head of School at the same school. Prof. Parameswaran received his B. Eng. Degree from Monash University and his Ph.D. from the University of Queensland in Australia. His research interests are in System Level Synthesis, Low power systems, High Level Systems, Network on Chips and Secure and Reliable Processor Architectures. He is the Editor-in-Chief of IEEE Embedded systems Letters. He is or has been on the editorial boards of IEEE Transactions on Computer Aided Design, ACM Transactions on Embedded Computing Systems, the EURASIP Journal on Embedded Systems and the Design Automation of Embedded Systems. He has served on the Program Committees of Design Automation Conference (DAC), Design and Test in Europe (DATE), the International Conference on Computer Aided Design (ICCAD), the International Conference on Hardware/Software Codesign and System Synthesis (CODES-ISSS), and the International Conference on Compilers, Architectures and Synthesis for Embedded Systems (CASES).
Day 2
Tutorial 5 : Secure Circuits and Systems (Starts at 9:30 AM)
Speakers:
Makoto Ikeda, University of Tokyo
Makoto Nagata, Kobe University
Shivam Bhasin, Nanyang Technical University
Simha Sethumadhavan, Columbia University
Hardware acceleration of Advanced Cryptography
Abstract:
This talk will cover basics of hardware accelerator designs, especially for the Elliptic-curve based public-key crypto-systems, across the design space for smallest ever design to the fastest ever design. This talk will also cover several trials on the advanced cryptography designs, including pairing engine design, Paillier crypto-system design, and Lattice-based crypto-system based on learning with errors (LWE) problem.
Speaker Bio:
Makoto Ikeda received the BE, ME, and Ph.D. degrees in electrical engineering from the University of Tokyo, Tokyo, Japan, in 1991, 1993 and 1996, respectively. He is a professor at the University of Tokyo. His research interests including hardware security, asynchronous circuits design, smart image sensor for 3-D range finding, and time-domain circuits for associate memories. Prof. Ikeda is Program Vice-Chair of International Solid-State Circuits Conference 2020 (ISSCC 2020). He was a technical program chair (2016-2017), a symposium chair and an executive committee member for the Symposium on VLSI circuits, a technical program chair for Asian Solid-State Circuits Conference 2015 (A-SSCC 2015), and also a chair for IEEE SSCS Japan Chapter. He is a senior member of IEEE, IEICE Japan, and member of IPSJ and ACM.
Side-channel attack analysis and simulation techniques
Abstract:
The talk will envision the design of IC chips toward side channel attack resiliency. Firstly, power noise simulation techniques of IC chips will be overviewed that are generally applicable to power integrity and electromagnetic compatibility (EMC). Then, the challenges about the deployment of such simulation techniques for the analysis of side-channel information leakage over power delivery networks will be discussed. Chip-package-system board (CPS) simulation techniques will reinforce IC chip designers to achieve the higher level of hardware security.
Speaker Bio:
Makoto Nagata received the B.S. and M.S. degrees in physics from Gakushuin University, Tokyo, in 1991 and 1993, respectively, and a Ph.D. in electronics engineering from Hiroshima University, Hiroshima, in 2001. He is currently a professor of the graduate school of science, technology and innovation, Kobe University, Kobe, Japan.
Makoto Nagata is chairing the Technology Directions subcommittee for International Solid-State Circuits Conference (ISSCC). He has also served as an associate editor for IEEE Transactions on VLSI Systems since 2015.He was a technical program chair (2010-2011), a symposium chair and an executive committee member for the Symposium on VLSI circuits, and also a chair for IEEE SSCS Kansai Chapter.
From Known Attacks to New Exploits: Recent Development & Open Problems
Abstract:
Hardware Security has been constantly troubled by implementation attacks like side-channel attacks and fault injection attacks in the past two decades. Recent years have seen a development of novel and advanced exploits based on implementation attacks ranging from simple embedded micro-controllers to high-end cloud servers. The advancement has been reported along multiple axes: remote attacks (meltdown, spectre, rowhammer), combined attacks (side-channel and fault attacks), deep attacks (deep-round attacks on cryptography, AI-based attacks), one fault only attacks (persistent fault attacks on protected design), side-channel/fault attacks on AI etc. This tutorial will highlight some of the advanced attacks reported in the recent years highlighting the key exploits and potential impact. Finally, we take a general look on open research problems towards a secure system design.
Speaker Bio:
Shivam Bhasin is a Senior Research Scientist and Programme manager (Cryptographic engineering) Centre for Hardware Assurance in Temasek laboratories, Nanyang Technical University (TL@NTU), Singapore since 2015. His research interests include embedded security, trusted computing and secure designs. He received his PhD from Telecom Paristech in 2011, Master’s from Mines Saint-Etienne, France in 2008 and Bachelor’s from UP Tech, India in 2007. Before NTU, Shivam held position of Research Engineer in Institut Mines-Telecom, France. He regularly publishes at top peer reviewed journals and conferences.
The End of Moore’s Law and its Implications for System Security
Abstract:
The field of computer architecture has changed in fundamental ways in the past few years. For several decades computer architects were able to improve computer system performance by leveraging silicon technology improvements alongside optimizing common program behaviors. Both of these tasks have become increasingly difficult. On the technology side, transistor voltage scaling has slowed down to the point that many now believe that future computer advances will have to be achieved without advances in silicon technology. On the software side, rapid growth of the software ecosystem has made identification of common behaviors very difficult. In this talk we will discuss how these trends may impact development and deployment of security solutions.
Speaker Bio:
Simha Sethumadhavan is an Associate Professor of Computer Science at Columbia University. Simha’s research work at Columbia is focused on finding practical solutions to problems in the area of cybersecurity and computer architecture. He is a recipient of an Alfred P. Sloan Research Fellowship, the NSF CAREER award and an IBM co-operative research award. His work has received nine best paper awards for his work on computer security and computer architecture, and his team has successfully taped out three novel computing chips (e.g., an analog-digital computing chip) on limited budgets.
His teams work on identifying security vulnerabilities resulted in fixes to major products such as mobile phone processors and web browsers used by millions of users, and his work on hardware security is actively considered by standards organizations. He has served on the Federal Communications Commission Downloadable Security Technical Advisory Committee. He is the Founder & CEO of Chip Scan Inc., a hardware security company focussed on finding and mitigating hardware backdoors. Simha obtained his PhD from UT Austin in 2007.
Pre-requisite:
Basic understanding of VLSI and cryptography
Day 2
Tutorial 6: Resiliency and Testability: Key Drivers for Self-Driving Vehicles (Starts at 9:30 AM)
Speakers:
J. A. Abraham, University of Texas, Austin, USA
Shawn Blanton, Carnegie Mellon University, USA
Abhijit Chatterjee, Georgia Tech University, USA
Nirmal Saxena, NVidia, USA
Resilient Computing: Imperative for Autonomous Systems
Abstract:
Advances in semiconductor technology have enabled increased performance and reduced costs of integrated circuits, making computers pervasive in society. As intelligent systems are being used in many critical applications, such as autonomous cars, they need to continue operating correctly in spite of design bugs, manufacturing defects, and failures during operation due to wearout or external disturbances. Systems must also ensure that they are immune to external malicious attacks.
This tutorial will address the problems and available solutions to developing resilient systems, including dealing with manufacturing test escapes, undetected bugs in the hardware, errors during operation, and security attacks. Verifying that complex designs implement their specifications correctly has to deal with enormous state spaces, more than the number of protons in the universe. Techniques to deal with this include powerful abstractions of the design behavior, using knowledge of the design, learning
methods, and innovative techniques to quickly expose bugs. Errors from manufacturing test escapes and wearout during operation need to be detected during operation without excessive overhead. This requires techniques which will check the computations for correct results, including exploiting the characteristics of application programs. On-chip circuitry which facilities testing of embedded modules could also be adapted for this purpose. Finally, these systems could be attacked during the design and manufacturing process with Trojan circuitry, as well during operation through networks which are necessary for monitoring and control of the systems. Unlike random failures, such attacks could be focused, requiring on-line (concurrent) checks directed at detecting the attack signatures.
Speaker Bio:
J. A. Abraham: Jacob A. Abraham is Professor of Electrical and Computer Engineering and at the University of Texas at Austin. He is also the director of the Computer Engineering Research Center and holds a Cockrell Family Regents Chair in Engineering. He received his Ph.D. in Electrical Engineering and Computer Science from Stanford University in 1974. He was on the faculty of the University of Illinois, Urbana, from 1975 to 1988. His research interests include VLSI design, verification, test, fault tolerance and security, as well as the use of non-invasive techniques to assess cognition in human subjects including healthy adults and Parkinson’s patients. He has published extensively, has received many “best paper” awards, and has been included in the ISI list of highly cited researchers. He has supervised more than 90 Ph.D. dissertations, and is particularly proud of the accomplishments of his students, many of whom occupy senior positions in academia and industry. He has been elected Fellow of the IEEE as well as Fellow of the ACM, and is the recipient of the 2005 IEEE Emanuel R. Piore Award, the 2017 Jean-Claude Laprie Award, the IEEE Test Technology Technical Committee Lifetime Contribution Medal, and the Achievement Award from the European Design Automation Association in 2019.
Yield Learning in 7nm Semiconductor Technologies: Test Chip Design
Abstract:
Test is the gatekeeper for both yield and quality. Quality can be modulated by controlling the type of tests applied in the manufacturing environment. But what about yield? Understanding test failures through the diagnosis of actual product ICs is extremely challenging because they are, of course, designed to implement a customer function, and not for providing feedback related to yield. We describe a methodology for solving this problem. It is common practice for design houses (e.g., Nvidia and Qualcomm), IC foundries (Global Foundries and TSMC), and integrated device manufacturers (IDMs) such as Samsung and Intel to fabricate test chips that have functional characteristics similar to customer products. These test chips are not meant to be sold to customers but are instead example ICs that provide feedback about the design methodology and the underlying fabrication technology. Because test chips are not sold for profit, their volume is typically not tremendously high so that cost is minimized. More importantly, the design of a test chip is currently ad hoc in nature in that they are typically composed of smaller portions of existing or past designs that have been scaled to the current technology node. Moreover, such designs are not optimal in that they are not ideal characterization vehicles (CVs) for providing design and fabrication feedback.
In this tutorial, a new type of logic characterization vehicle (LCV) that simultaneously optimizes design, test, and diagnosis for yield learning is described. The Carnegie-Mellon LCV is a test chip composed of logic standard cells that uses constant-testability theory and logic/layout diversity to create a parameterized design that exhibits both front- and back-end demographics of a product-like, customer design. Analysis of various CMU-LCV designs (one of which has >4M gates) demonstrates that design time and density, test and diagnosis can all be simultaneously optimized. Several of our designs have been taped out in volume in state-of-the-art technologies with first test results expected back in a few weeks.
Speaker Bio:
Shawn Blanton: Shawn Blanton is a professor in the Department of Electrical and Computer Engineering at Carnegie Mellon University where he formerly served as director of the Center for Silicon System Implementation, an organization that consisted of 18 faculty members and over 80 PHD students that focused on the design and manufacture of silicon-based systems. He currently serves as the Associate Director of the SYSU-CMU Joint Institute of Engineering (JIE, http://jie.cmu.edu/). He received the Bachelor’s degree in engineering from Calvin College in 1987, a Master’s degree in Electrical Engineering in 1989 from the University of Arizona, and a Ph.D. degree in Computer Science and Engineering from the University of Michigan, Ann Arbor in 1995.
Professor Blanton’s research interests are housed in the Advanced Chip Testing Laboratory (ACTL, www.ece.cmu.edu/~actl) and include the design, verification, test and diagnosis of integrated, heterogeneous systems. He has published many papers in these areas and has several issued and pending patents in the area of IC test and diagnosis. Prof. Blanton has received the National Science Foundation Career Award for the development of a microelectromechanical systems (MEMS) testing methodology and two IBM Faculty Partnership Awards. He is a Fellow of the IEEE, and is the recipient of the 2006 Emerald Award for outstanding leadership in recruiting and mentoring minorities for advanced degrees in science and technology.
Machine Learning Assisted Validation, Off and On-Line Test and Tuning of Advanced Mixed-Signal/RF Circuits and Systems
Abstract:
The performance of advanced mixed-signal/RF circuits and systems must be guaranteed in the presence of: (a) design uncertainties that arise from the inability to validate the design against “electrical bugs” that are difficult to verify using simulation models and (b) SoC failures that arise from silicon manufacturing process variations, random defects and electrical degradation in the field. In post-silicon debug, the goal is to discover if there are discrepancies between observed and expected chip behavior. If a discrepancy is observed, the next step is to understand the nature of the discrepancy, its root cause and to deliver to the circuit designer a model of the discrepancy to facilitate correction of the design. In post-manufacture testing and tuning, a large gamut of complex device specification must be tested, sometimes without access to high-end test instrumentation (such as when performing built-in test). Moreover, advanced devices need to be tuned for post-manufacture yield recovery across hundreds of tuning bits using iterative testing and tuning procedures (e.g. for anticipated 5G communications systems). In this tutorial, we discuss novel co-operative test stimulus generation and machine learning assisted response analysis algorithms for post-silicon validation and post-manufacture testing/tuning of complex mixed-signal/RF circuits and systems. The results obtained from application of the core ideas to test cases from industry will be presented. Application of on-line anomaly detection algorithms to collision avoidance in autonomous traffic will be discussed.
Speaker Bio:
Abhijit Chatterjee: Abhijit Chatterjee is a professor in the School of Electrical and Computer Engineering at Georgia Tech and a Fellow of the IEEE. He received his Ph.D in electrical and computer engineering from the University of Illinois at Urbana-Champaign in 1990. Abhijit Chatterjee received the NSF Research Initiation Award in 1993 and the NSF CAREER Award in 1995. He has received seven Best Paper Awards and three Best Paper Award nominations. His work on self-healing chips was featured as one of General Electric’s key technical achievements in 1992 and was cited by the Wall Street Journal. In 1995, he was named a Collaborating Partner in NASA’s New Millennium project. In 1996, he received the Outstanding Faculty for Research Award from the Georgia Tech Packaging Research Center, and in 2000, he received the Outstanding Faculty for Technology Transfer Award, also given by the Packaging Research Center. In 2007, his group received the Margarida Jacome Award for work on VIZOR: Virtually Zero Margin Adaptive RF from the Berkeley Gigascale Research Center (GSRC).
Abhijit Chatterjee has authored over 425 papers in refereed journals and meetings and has 21 patents. He is a co-founder of Ardext Technologies Inc., a mixed-signal test solutions company and served as chairman and chief scientist from 2000-2002. He served as the chair of the VLSI Technical Interest Group at Georgia Tech from 2010-2012. His research interests include error-resilient signal processing and control systems, mixed-signal/RF/multi-GHz design and test and adaptive real-time systems.
Road to Resilient Autonomous Cars is Paved with Testability & Redundancy
Abstract:
According to the 2015 vehicular accidents report [www.nhtsa.gov], there were more than 35000 fatal crashes and more than 6 million non-fatal crashes. Translating the 35K fatal crashes, over 3 trillion driven miles, to a FIT (failures in time, time = one billion hours) rate we get a fatality FIT rate in the range 250-500. A drive system, in a fully autonomous car, that replaces the human driver must at least be an order of magnitude more resilient. In fact the ISO 26262 Auto Safety Standard, stipulates a probabilistic metric for hardware failures (PMHF) to be at most 10 FITs. This requirement is almost two orders of magnitude improvement over driver related fatal accident FIT rate; notwithstanding, the fact that not all hardware failures result in fatalities. Autonomous or self-driving car initiative is creating a new center stage for resilient computing and design for testability. This is very apparent from reading the ISO26262 specification, which is about the functional safety for automotive equipment applicable throughout the lifecycle of all automotive electronic and electrical safety-related systems. By way of a detailed review of the ISO26262 standard, this tutorial pays tribute to all of the important and significant ideas that have come through the past 40+ years of research in fault-tolerant computing and design-for-testability. One of the key use cases for self-driving car is neural-network based deep learning. Reliability models that explore the dynamic trade-offs between resiliency and performance requirements for deep learning are examined. Deep neural networks use the computational power of massively parallel processors in applications such as autonomous driving. Autonomous driving demands resiliency (as in safety and reliability) and trillions of operations per second of computing performance to process sensor data with extreme accuracy. This talk examines various approaches to achieve resiliency in autonomous cars and makes the case for design diversity based redundancy as a viable solution.
Speaker Bio:
Nirmal Saxena: Nirmal R. Saxena is currently a distinguished engineer at NVIDIA and is responsible for high-performance and automotive resilient computing. From 2011 through 2015, Nirmal was associated with Inphi Corp as CTO for Storage & Computing and with Samsung Electronics as Sr. Director working on fault-tolerant DRAM memory and storage array architectures. During 2006 through 2011, Nirmal held roles as a Principal Architect, Chief Server Hardware Architect & VP at NVIDIA. From 1991 through 2009, he was also associated with Stanford University’s Center for Reliable Computing and EE Department as Associate Director and Consulting Professor respectively. During his association with Stanford University, he taught courses in Logic Design, Computer Architecture, Fault-Tolerant Computing, supervised six PhD students and was co-investigator with Professor Edward J. McCluskey on DARPA’s ROAR (Reliability Obtained through Adaptive Reconfiguration) project. Nirmal was the Executive VP, CTO, and COO at Alliance Semiconductor, Santa Clara. Prior to Alliance, Nirmal was VP of Architecture at Chip Engines. Nirmal has served in senior technical and management positions at Tiara Networks, Silicon Graphics, HaL Computers, and Hewlett Packard.
Nirmal received his BE ECE degree (1982) from Osmania University, India; MSEE degree (1984) from the University of Iowa; and Ph.D. EE degree (1991) from Stanford University. He is a Fellow of IEEE (2002) and was cited for his contributions to reliable computing.